

Home >
M-VADER
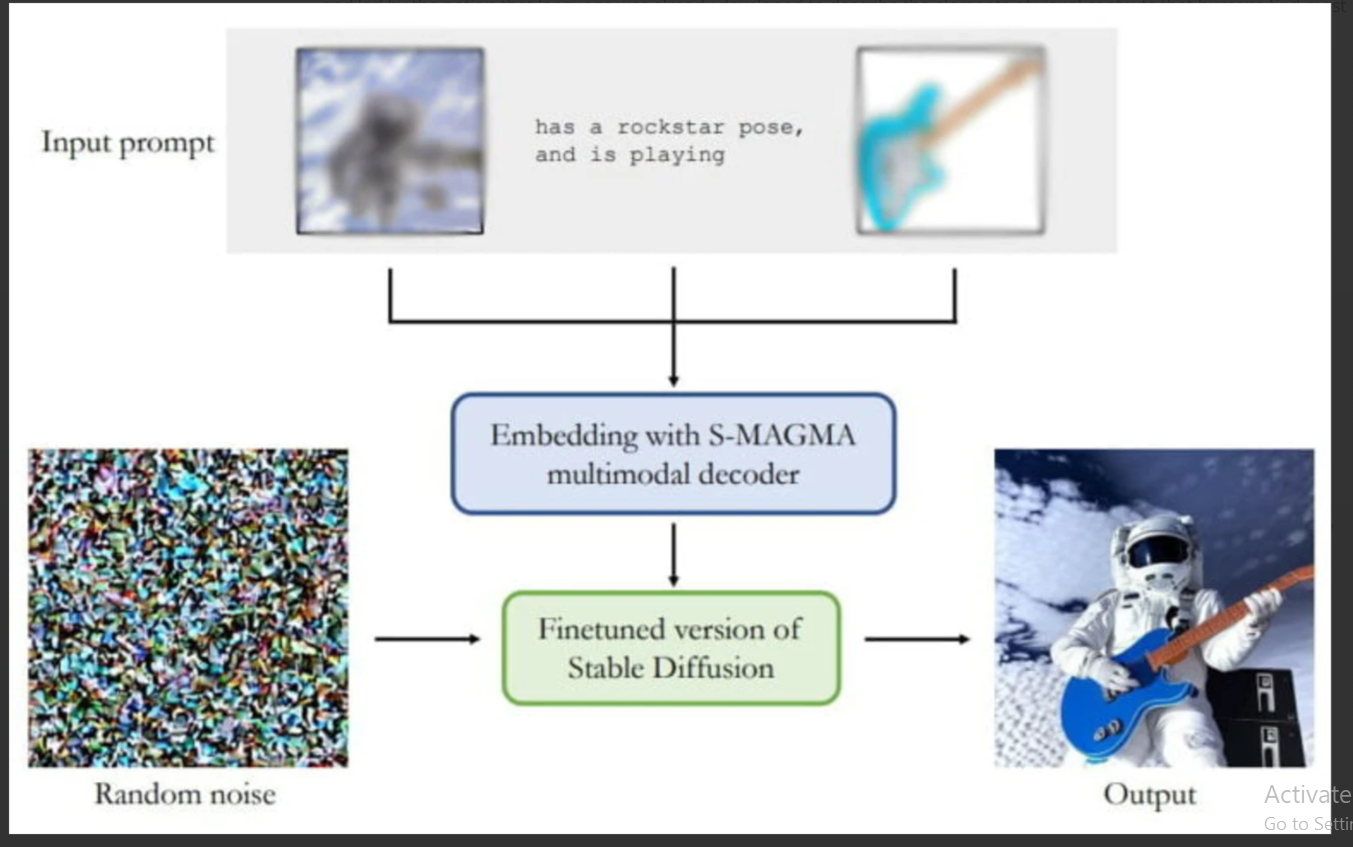
Innovative diffusion model M-VADER, created by Aleph Alpha in partnership with TU Darmstadt, is capable of combining multimodal inputs, such as text and images, to produce fresh image ideas.
M-VADER can incorporate both visual and text cues, in contrast to earlier generative AI models that only used text cues to generate images. It makes use of the cutting-edge S-MAGMA embedding model, which combines vision-language model characteristics with biases tailored for semantic search. This enables the generation of more complex and contextually rich images based on a variety of input configurations.
User objects:
- Graphic designers
- Digital artists
- Content creators
- Marketers
- Multimedia developers
- Researchers in AI and visual processing
- Product developers
- Film and animation professionals
>>> Please use: ChatGPT Free – Version from OpenAI
DEMO
Similar Apps

Microsoft Kosmos 1
MLLM (Multimodal Large Language Models)

GPT 4
MLLM (Multimodal Large Language Models)