

Home >
Microsoft Kosmos 1
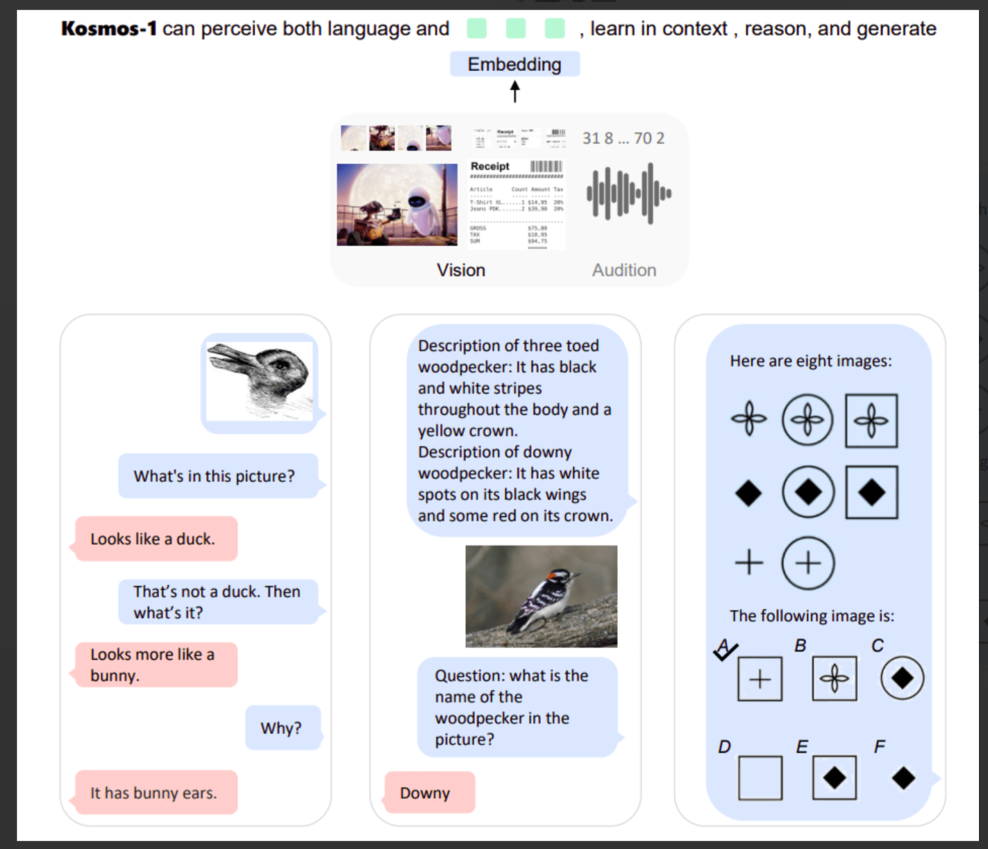
The Kosmos-1 multimodal large language model (MLLM) from Microsoft can process visual and audible cues in addition to text. Kosmos-1 offers applications like image captioning, visual question answering, and more, in contrast to conventional language models that only respond to text prompts. The model is developed using large multimodal datasets that include text, image-text pairings, and a combination of words and images. It excels at a variety of tasks including visual captioning, OCR, zero-shot image classification, and visual dialogue.
User objects: Developers, researchers, content creators, visual artists, educators, and businesses requiring multimodal AI interactions.
>>> Use Chat GPT Demo with OpenAI’s equivalent smart bot experience
DEMO

Similar Apps
Openai Codex
Alternative Language Models
nanoGPT minGPT
Alternative Language Models

Muse
Alternative Language Models

MT NLG by Microsoft and Nvidia AI
Alternative Language Models

DeepMind RETRO
Alternative Language Models

MPT 7B Mosaic ml
Alternative Language Models