
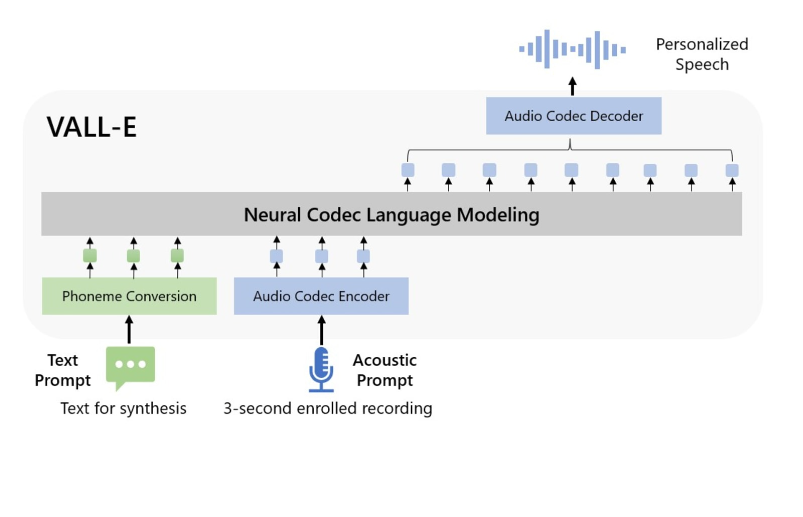
With just a 3-second audio sample, Microsoft’s new text-to-speech model, VALL-E, can replicate anyone’s voice while maintaining the speaker’s emotional tone and setting. When paired with AI models like GPT-3, this advanced model has applications in high-quality text-to-speech, speech editing, and content creation.
VALL-E, in contrast to conventional text-to-speech techniques, uses EnCodec technology to produce audio codec codes from text and acoustic inputs. It can mimic how a voice might utter certain words or phrases by dissecting them into individual parts, or “tokens,” through analysis. Microsoft, however, recognises the problems that could arise, such as voice spoofing or impersonation, and advises developing detection algorithms to spot synthesised speech. Microsoft pledges to use their AI principles in VALL-E’s continuous development as a safety measure.
User objects:
- Content creators
- Filmmakers and animators
- Podcasters
- Advertisers and marketers
- Audio book producers
- Voiceover artists
- Developers creating voice-based apps
- Journalists and reporters
- Speech therapists and trainers
- Entertainment industry professionals.
>>> Use Chat GPT Demo with OpenAI’s equivalent smart bot experience
DEMO
Similar Apps

Excel

Whisper by OpenAI

Voicebox by Meta

Speak
